Technical SEO Implementation
Turn audit and topology findings into real site changes.
View technical SEOTopoRank case study
Available for contract web work at $55/hr
A technical look at how TopoRank crawls a site, strips template noise, discovers semantic clusters, scores link support, and turns internal linking into a measurable optimization loop.
Technical SEO systems
Most internal linking advice still sounds like a spreadsheet exercise: find a keyword, find a matching page, add an anchor, repeat until the export looks busy. That is not how modern retrieval systems understand a site. Search systems parse a website as a graph of documents, templates, topical neighborhoods, entity relationships, and semantic intent.
TopoRank was built around that graph-shaped problem. It is a proprietary tool built and used by The Web Guy for crawl analysis, semantic topology review, internal link planning, and implementation QA. It does not begin with a static keyword list. It crawls the site, removes global boilerplate, embeds the remaining main content, discovers the semantic clusters that already exist, and then asks whether the physical URL structure and internal links support or contradict those clusters.
The version shown here is the internal working dashboard, not a public SaaS product. A public-facing variant of TopoRank is expected in late 2026 or early 2027 after the reporting, permissions, project setup, export flows, and re-harvest workflow are packaged for outside users.
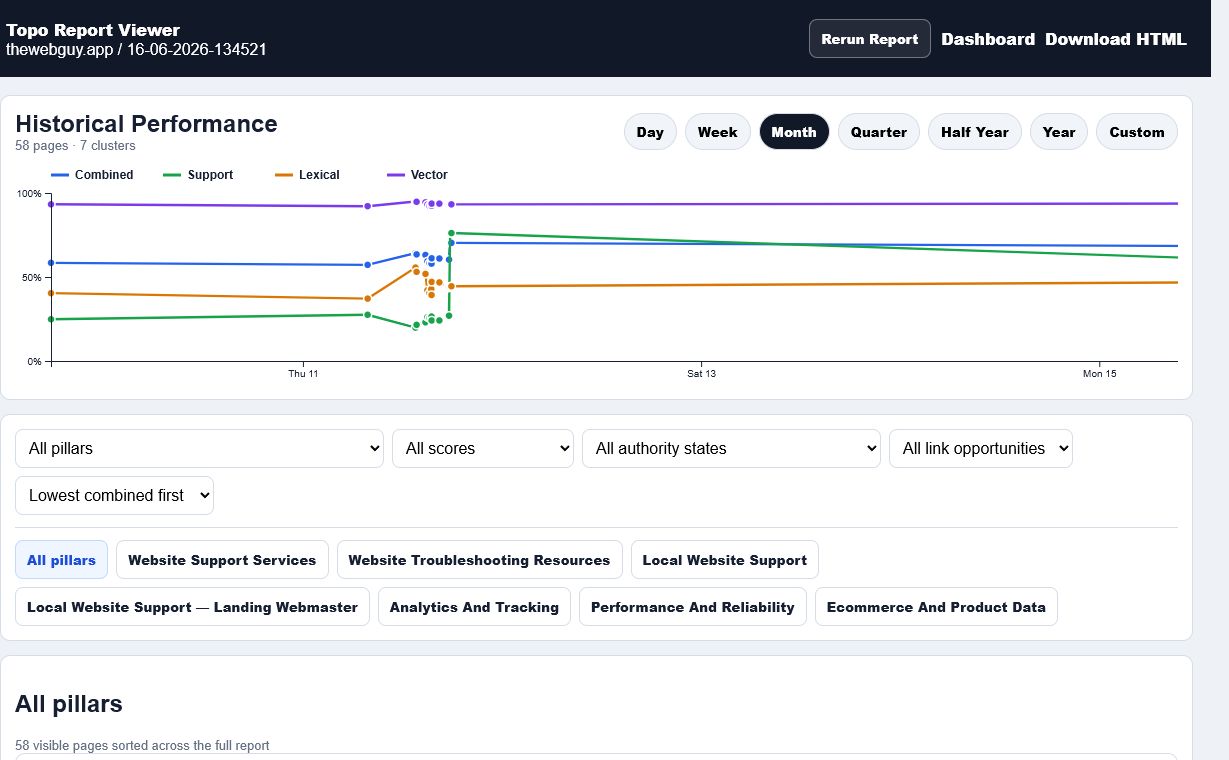
The June 12, 2026 crawl of thewebguy.app produced the first useful proof point: 56 crawled pages, 2 discovered clusters, 69.7% average combined topology, 58.8% semantic resonance, 36 weak pages, 9 strong pages, and 448 suggested link opportunities. After the TopoRank update, a June 16 local re-harvest requested and retained 7 populated pillar profiles across 58 crawled pages, with 72.2% average combined topology, 61.5% semantic resonance, 27 weak pages, 11 strong pages, and 464 suggested link opportunities. The interesting part was not that the site had no links. It was that many links were template-heavy, so important pages needed more body-level support.
If this article describes the symptom on your site, compare Crawl Analysis & Internal Linking and Technical SEO Implementation before turning the problem into a request.
If the first fix path is not quite right, SEO Developer Help may be the better service or skill page. You can also use Contact once you have the URL, symptom, timeline, and what should happen instead.
| What TopoRank is today | TopoRank is currently an internal technical SEO and content topology workbench. The Web Guy uses it to crawl a site, queue and compare dated harvests, inspect page-level topology scores, review cluster placement, find weak contextual support, and test whether edits improve the site graph. | Queue local crawls and store dated report snapshots., Open report views for a domain, local build, or historical crawl folder. | Crawl Analysis & Internal Linking |
| The shift from keyword string matching to vector topology | Legacy internal linking treats pages as bags of keywords. If a source page says analytics and a target page says analytics, the rule says to connect them. That can still catch obvious opportunities, but it misses the real structure of a site: whether a page supports a pillar, bridges two subtopics, or accidentally bleeds into a different silo. | It cannot distinguish body-level editorial links from repeated template links., It misses pages whose meaning is close but whose vocabulary is different. | Crawl Analysis & Internal Linking |
| The math behind TopoRank | TopoRank starts with autonomous cluster discovery. The crawler harvests pages, extracts main content, creates vector representations, and lets the site reveal its own topical clusters instead of forcing every page into a third-party keyword taxonomy. | Lexical score compares page vocabulary against expected cluster terms., Vector score compares page embeddings to the cluster or topic embedding. | Crawl Analysis & Internal Linking |
| The thewebguy.app crawl baseline | The first TopoRank report for thewebguy.app was generated on June 12, 2026 at 01:54:51. It crawled 56 pages and found 448 suggested link opportunities. The average vector score was high at 93.2%, which means pages were semantically close to the site's topic space. The average lexical score was much lower at 43.8%, which means the vocabulary and page-specific wording were not always reinforcing the discovered clusters. | 56 pages crawled, 2 primary clusters discovered | Crawl Analysis & Internal Linking |
| Implementation details that keep the graph honest | The biggest risk in a topology score is accidentally measuring the template instead of the document. A crawler that treats the header, footer, sticky CTA, service nav, card grid, and repeated FAQ modules as unique page text will overestimate topical alignment because every page starts to look like every other page. | Canonical URL normalization so slash variants and duplicate paths do not split page authority., Boilerplate stripping so navigation, footer, and repeated CTA text do not dominate semantic scoring. | Crawl Analysis & Internal Linking |
| Turning weak pages into stronger pages | The remediation pass did not stop at this article. The site now includes route-aware TopoRank support paths that add contextual links from weak or borderline pages toward related services, skills, blog posts, FAQ, rate, and implementation pages. The goal is to turn repeated template support into page-specific support that a crawler can explain. | Route-aware contextual support links for service, skill, blog, contact, and index pages that TopoRank marked as useful bridge routes., A dedicated topology bridge section that appears only when a page has page-specific recommendations. | Crawl Analysis & Internal Linking |
| Low-weight pages were not always orphaned | The report surfaced an implementation detail that many audits miss: the weak pages were not necessarily isolated by raw link count. They were weak because the strongest links were often global or repeated. TopoRank distinguishes incoming count from semantic support. | Website Tracking and Data Troubleshooting: 55.0% combined, 64.3% support, 12.4% lexical, 92.9% vector., SEO Audit Implementation Help: 57.6% combined, 77.3% support, 12.5% lexical, 92.9% vector. | Crawl Analysis & Internal Linking |
| The optimization loop | TopoRank's report viewer is not just a static audit. It includes an editing workbench that loads the isolated main content for a page. The user can inspect the page's current cluster fit, view recommended link targets, highlight text in the editor, and inject an anchor around the selected phrase. | Open the report for the crawl snapshot., Filter by weak combined score or weak semantic link support. | Crawl Analysis & Internal Linking |
| How this post routes link weight | This article is itself a topology node. It is not useful if it only describes the system and sits disconnected from the pages that need support. The post therefore points into the technical pages that TopoRank identified as needing more contextual reinforcement. | Use contextual body links instead of only navigation links., Link from service and skill pages where the topic naturally overlaps. | Crawl Analysis & Internal Linking |
| What the local re-harvest changed | After the route-aware support pass and TopoRank update, I re-harvested the local thewebguy.app build with TopoRank set to request 7 main pillars. The crawl finished on June 16, 2026 at 13:45:38. It crawled 58 pages and retained all 7 requested pillar profiles in the report. | 58 local pages crawled in the re-harvest., 7 main pillars requested and 7 populated pillar profiles retained in the final report. | Crawl Analysis & Internal Linking |
| Why sitewide scores can dip while the target page improves | A topology audit can feel counterintuitive because the target URL may improve while the sitewide average barely moves or even softens. That is not automatically a failed edit. A fresh harvest can include new pages, changed templates, different crawl depth, more discovered links, and new sections that alter the denominator. | Compare identical crawl scopes when making sitewide claims., Use page-level score movement to judge a specific edit. | Crawl Analysis & Internal Linking |
| How FAQ questions and GA4 journeys feed the content loop | The analytics work on the site turns this from a one-time internal-linking exercise into a feedback loop. Search input, scroll-section visibility, button clicks, navigation context, exit-intent responses, contact form fills, and FAQ questions can all become evidence about what visitors were trying to understand before they converted or left. | Answer as an FAQ when the question is specific to one service, skill, or troubleshooting page., Answer as a blog post when the same question appears across several pages or describes a broader workflow. | Crawl Analysis & Internal Linking |
TopoRank is currently an internal technical SEO and content topology workbench. The Web Guy uses it to crawl a site, queue and compare dated harvests, inspect page-level topology scores, review cluster placement, find weak contextual support, and test whether edits improve the site graph.
The public version is not live yet. The internal dashboard is useful because it shows the workflow before it is polished into a product: start a crawl, watch queue status, open a dated report, inspect the pages that need support, move between scoring panels, and use the editing workbench to preview link and content changes.
That matters for client work because TopoRank is not being described as theory. It is already part of The Web Guy's implementation process for internal link cleanup, technical SEO planning, content architecture checks, and re-harvest comparisons.
Legacy internal linking treats pages as bags of keywords. If a source page says analytics and a target page says analytics, the rule says to connect them. That can still catch obvious opportunities, but it misses the real structure of a site: whether a page supports a pillar, bridges two subtopics, or accidentally bleeds into a different silo.
Vector topology starts from the document neighborhood instead. Each page becomes a point in semantic space. Pages that explain related intent sit closer together even when they do not repeat the same exact phrase. That matters for sites where a business problem crosses terms: GA4, forms, CRM handoffs, tracking scripts, webhooks, dashboards, and conversion reporting can all describe the same operational failure.
TopoRank's job is to compare those semantic coordinates against the site's actual link graph. A page can have many incoming links and still have weak support if those links are mostly navigation, footer, cards, or global template elements. The crawl therefore separates link count from contextual support.
TopoRank starts with autonomous cluster discovery. The crawler harvests pages, extracts main content, creates vector representations, and lets the site reveal its own topical clusters instead of forcing every page into a third-party keyword taxonomy.
The updated June 16 local crawl requested 7 main pillars and retained all 7 as populated profiles: Website Support Services, Website Troubleshooting Resources, Local Website Support, Local Website Support — Landing Webmaster, Analytics and Tracking, Performance and Reliability, and Ecommerce and Product Data. That behavior is useful because it shows the updated TopoRank model producing a more granular site structure instead of collapsing the site back into only a few broad clusters.
URL hierarchy is then used as a structural weight. A page under /services/ has a different declared role than a page under /blog/ or /skills/. If the vector engine says a page belongs near a business-service cluster but the URL and link graph isolate it as a loose article, TopoRank flags the mismatch as structural dissonance or silo bleed.
The tool also strips boilerplate before scoring. Header menus, footer columns, repeated CTAs, global sidebars, and common navigation can overwhelm the text if they are treated as page-specific meaning. TopoRank uses fuzzy thresholding across pages to suppress those repeated blocks and analyze the semantic content that is actually unique to the page.
The first TopoRank report for thewebguy.app was generated on June 12, 2026 at 01:54:51. It crawled 56 pages and found 448 suggested link opportunities. The average vector score was high at 93.2%, which means pages were semantically close to the site's topic space. The average lexical score was much lower at 43.8%, which means the vocabulary and page-specific wording were not always reinforcing the discovered clusters.
The average authority/support score was 74.7%, but the report repeatedly marked technical pages as boilerplate-heavy. That is the important distinction. A page can show 55 incoming internal links because it appears in navigation and footer structures, but still lack enough contextual support in paragraphs, article bodies, or related explanatory sections.
The crawl labeled semantic resonance as weak at 58.8%. That does not mean the site was off-topic. It means the relationships between pages were not strong enough yet. TopoRank's recommendation pattern was consistent: add more contextual same-topic links and reduce reliance on repeated template links.
The biggest risk in a topology score is accidentally measuring the template instead of the document. A crawler that treats the header, footer, sticky CTA, service nav, card grid, and repeated FAQ modules as unique page text will overestimate topical alignment because every page starts to look like every other page.
TopoRank avoids that by isolating canonical URLs, normalizing internal links, suppressing repeated blocks, and scoring the remaining main content against the discovered semantic cluster. The result is a cleaner read on page-specific meaning: the title, H1, intro, section headings, body copy, contextual anchors, and nearby explanatory links.
The link graph then separates raw internal link count from weighted support. A footer link and a sentence-level link are both internal links, but they do not carry the same semantic signal. Body links surrounded by relevant language are more useful because they tell the crawler why the source page and target page belong near each other.
The remediation pass did not stop at this article. The site now includes route-aware TopoRank support paths that add contextual links from weak or borderline pages toward related services, skills, blog posts, FAQ, rate, and implementation pages. The goal is to turn repeated template support into page-specific support that a crawler can explain.
The June 16 re-harvest shows movement, not completion. Weak pages dropped from the original 36-page baseline to 27 in the latest TopoRank summary, while strong pages increased from 9 to 11. At the row threshold level, 23 pages were still below 70% combined topology and 11 pages were at or above 80%. That means the site is stronger, but the remaining weak pages still need more body copy, clearer page identity, and better same-cluster routes.
That distinction matters. A responsible topology workflow should not mark a page strong just because a support module exists. It should re-harvest the site, check the new score distribution, and keep extending pages that still have weak lexical fit or boilerplate-heavy support.
The report surfaced an implementation detail that many audits miss: the weak pages were not necessarily isolated by raw link count. They were weak because the strongest links were often global or repeated. TopoRank distinguishes incoming count from semantic support.
For example, the Crawl Analysis and Internal Linking skill page had a 59.2% combined topology score, 66.0% support score, 23.4% lexical score, and 91.6% vector score. That shape says the page belongs in the right semantic neighborhood, but the copy and body-level routing need more reinforcement.
The Website Tracking and Data Troubleshooting post had the weakest combined score in the sampled report at 55.0%, with a 12.4% lexical score and 92.9% vector score. That is a classic vector-topology finding: the page is semantically near the right topic, but the visible wording and contextual link routes are not carrying enough explicit signal.
TopoRank's report viewer is not just a static audit. It includes an editing workbench that loads the isolated main content for a page. The user can inspect the page's current cluster fit, view recommended link targets, highlight text in the editor, and inject an anchor around the selected phrase.
The important piece is the re-harvest loop. After inserting a contextual link, the page can be re-scored against the same topology model. That gives a developer immediate feedback on whether the edit improved the page's combined topology, support, lexical fit, or vector alignment.
This changes internal linking from opinion to instrumentation. Instead of asking whether an anchor feels relevant, the workflow asks whether the source page, target page, and cluster centroid became more coherent after the link was added.
This article is itself a topology node. It is not useful if it only describes the system and sits disconnected from the pages that need support. The post therefore points into the technical pages that TopoRank identified as needing more contextual reinforcement.
The outbound links are intentionally specific: crawl analysis and internal linking for the method, production debugging for live-page verification, performance engineering for speed and rendering work, GA4/GTM measurement integrity for conversion-flow validation, REST API and webhook integrations for data handoffs, and WordPress plugin development for site-specific functionality.
The inbound links are also intentional. Site speed, ongoing webmaster support, performance engineering, production debugging, and crawl analysis pages can all naturally reference the TopoRank workflow because those pages already talk about real site behavior, recurring QA, crawl paths, and technical cleanup.
After the route-aware support pass and TopoRank update, I re-harvested the local thewebguy.app build with TopoRank set to request 7 main pillars. The crawl finished on June 16, 2026 at 13:45:38. It crawled 58 pages and retained all 7 requested pillar profiles in the report.
The sitewide numbers moved in the right direction. Average combined topology rose to 72.2%, average lexical fit rose to 52.5%, average vector fit held at 94.0%, average authority/support settled at 67.9%, and semantic resonance rose to 61.5%. Weak pages dropped to 27 and strong pages held at 11.
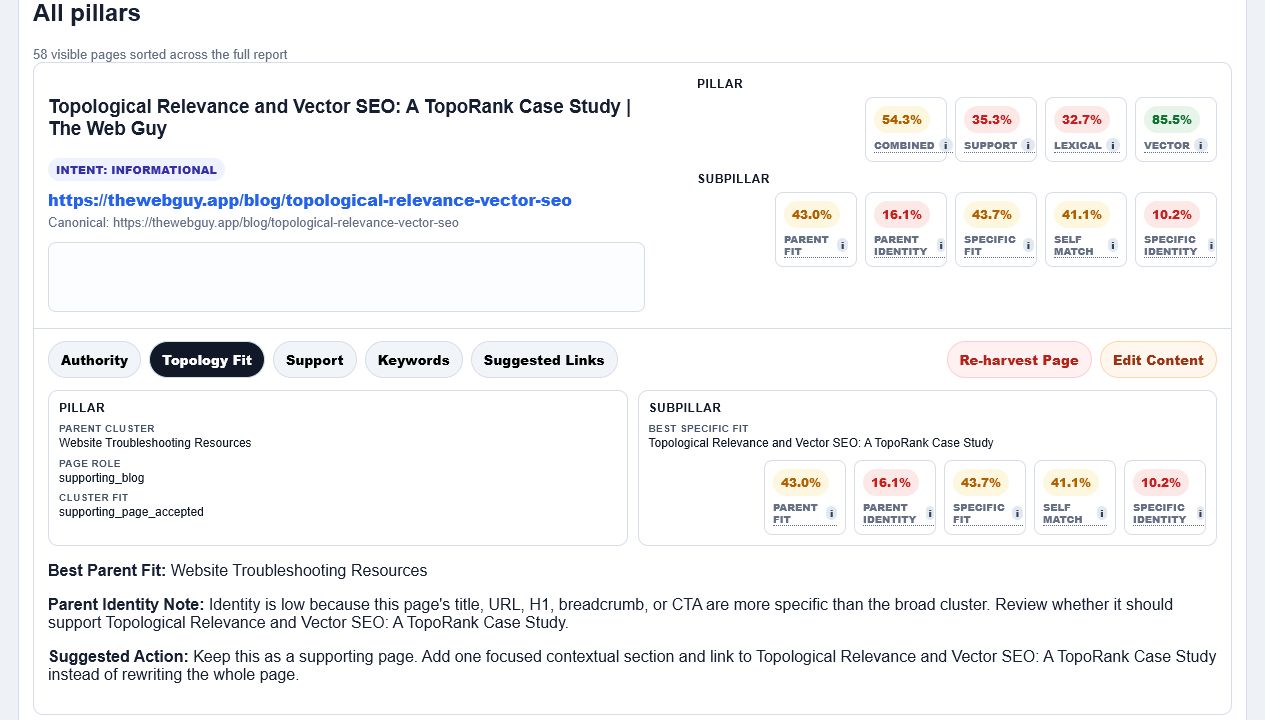
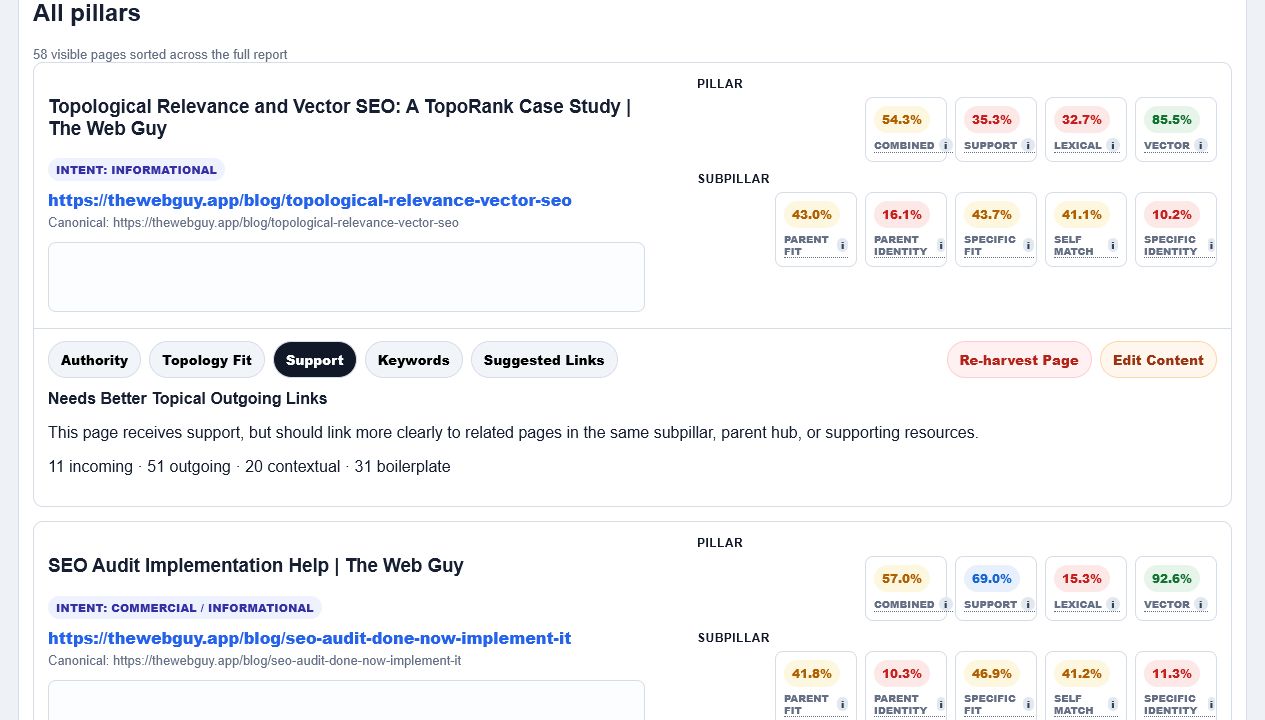
The new TopoRank post stayed in the Website Troubleshooting Resources pillar. That is a stricter and more useful placement for this article because the piece behaves like an explanatory troubleshooting resource rather than a pure service page. The article still needs better topical outgoing links: it scored 54.3% combined topology, 32.7% lexical fit, 85.5% vector fit, and 35.3% authority/support in this updated 7-pillar report.
A topology audit can feel counterintuitive because the target URL may improve while the sitewide average barely moves or even softens. That is not automatically a failed edit. A fresh harvest can include new pages, changed templates, different crawl depth, more discovered links, and new sections that alter the denominator.
For this pass, the production baseline and local crawl were not identical inputs. The June 12 production crawl had 56 pages. The local re-harvest had 58 pages because the development site had new functionality and the new case study itself. Comparing those totals as if they were the same sample would be sloppy.
The honest read is page-level first, cluster-level second, sitewide third. The target article became more topically explicit and better supported. The Measurement Integrity neighborhood now has another explanatory node. The sitewide resonance score still says the broader graph needs more contextual same-topic links across older pages.
The analytics work on the site turns this from a one-time internal-linking exercise into a feedback loop. Search input, scroll-section visibility, button clicks, navigation context, exit-intent responses, contact form fills, and FAQ questions can all become evidence about what visitors were trying to understand before they converted or left.
That matters for TopoRank because visitor questions often reveal missing semantic bridges. If several people ask a question from a tracking page, the answer may belong as an FAQ on that page. If the question keeps appearing from multiple pages, it may deserve a full blog post with contextual links back into the pages where the question was asked.
The choice between FAQ and blog post should be based on scope. A short clarification belongs on the page that produced the question. A repeated question that crosses GA4, forms, CRM handoff, search, crawl paths, or content architecture should become a deeper article that supports the whole cluster, or an internal tool if the review keeps repeating.
Fix options
These links connect the symptom in the article to the service or skill path that usually handles the fix.
Crawl Analysis & Internal Linking Use this when crawl exports, orphaned pages, crawl paths, internal link modules, and semantic link support need implementation.
Technical SEO Implementation Use this when topology findings need to become metadata, headings, redirects, schema, internal links, and site changes.
SEO Developer Help Use this when crawl topology findings need an SEO developer to turn internal-link, template, schema, redirect, and crawl recommendations into live site changes.
Production Debugging Use this when crawl findings need to be verified against real browser behavior, scripts, routes, forms, or production state.
Useful next links
These related pages connect this article to the hands-on services, skills, and request paths that usually solve the problem on a real site.
Crawl Analysis & Internal Linking Use Crawl Analysis & Internal Linking when crawl exports, orphaned pages, crawl paths, internal link modules, and semantic link support need implementation.
Technical SEO Implementation Use Technical SEO Implementation when topology findings need to become metadata, headings, redirects, schema, internal links, and site changes.
SEO Developer Help Use SEO Developer Help when crawl topology findings need an SEO developer to turn internal-link, template, schema, redirect, and crawl recommendations into live site changes.
Production Debugging Use Production Debugging when crawl findings need to be verified against real browser behavior, scripts, routes, forms, or production state.
Performance Engineering Use Performance Engineering when topology findings overlap with script weight, rendering, layout shift, caching, or Core Web Vitals cleanup.
GA4/GTM Measurement Integrity Use GA4/GTM Measurement Integrity when the same user journey has to be verified in analytics events, conversions, and reports.
REST API & Webhook Integrations Use REST API & Webhook Integrations when forms, CRMs, dashboards, webhooks, and APIs need to line up with the page flow being measured.
WordPress Plugin Development Use WordPress Plugin Development when site-specific functionality or admin workflows need durable implementation instead of fragile snippets.
Schema & Structured Data Use Schema & Structured Data when topology findings need structured data that matches visible page content, services, FAQs, products, and templates.
Automation & Internal Tools Use Automation & Internal Tools when repeated crawl checks, report comparisons, QA workflows, or link reviews should become an internal tool.
Analytics & Tracking Use Analytics & Tracking when topology, search, scroll, click, form, and FAQ-question events need to be measured in the same user journey.
Website Data Troubleshooting Use Website Data Troubleshooting when GA4, forms, CRMs, APIs, dashboards, and conversion records do not match the user's real path.
Tracking Scripts and Pixels Use Tracking Scripts and Pixels when the crawl or conversion path depends on scripts, pixels, events, and browser behavior being trustworthy.
Site Speed and Performance Cleanup Use Site Speed and Performance Cleanup when crawl findings overlap with slow rendering, heavy scripts, Core Web Vitals, or template weight.
Security, Hosting & Reliability Use Security, Hosting & Reliability when redirects, cache, SSL, Cloudflare, hosting, uptime, or reliability problems affect crawl and measurement trust.
Ongoing Webmaster Support Use Ongoing Webmaster Support when topology checks, content updates, analytics QA, and recurring site maintenance need a steady implementation loop.
Send the site, the crawl problem, or the pages that feel isolated. I can help turn topology findings into practical internal links, technical SEO edits, and implementation work.
More troubleshooting
These pages cover the nearby work that usually follows a topology audit.
Turn audit and topology findings into real site changes.
View technical SEOFind weak crawl paths, orphaned pages, and contextual link gaps.
View crawl analysisDesign scalable pages without creating thin isolated URL sets.
View programmatic SEOVerify whether the journey and conversion flow are measured correctly.
View measurement integrityFAQ
No. It crawls the site, strips repeated template content, embeds main content, discovers semantic clusters, and scores whether URL structure and internal links support those clusters.
Global navigation, footer links, and repeated modules can make every page look more similar than it really is. Stripping boilerplate helps the tool analyze page-specific meaning.
Yes. A page can have many template links but weak contextual support. TopoRank separates raw link count from body-level semantic support.
No. It is a diagnostic signal for site structure, semantic alignment, and internal links. Rankings still depend on search demand, competition, content quality, technical health, and many external signals.